


Table of contents
History of Kubernetes
Tech giant Google in 2003-04 started a project called Borg System. It was a large-scale internal cluster management system. It was designed to serve huge workloads for example running thousands of jobs, for different applications, across many clusters and thousands of servers.
Starting with Borg and later Omega Google mid-2014 introduced the Project Kubernetes and released it as an open source version of Borg.
Within a few months of its initial release companies like Microsoft, RedHat, IBM, and Docker joined the Kubernetes community.
Within a year the Kubernetes version 1.0 was released and later it was donated to the Cloud Native Computing Foundation by Google.

What is Kubernetes?
Kubernetes, also known as K8s, is an open-source system for automating the deployment, scaling, and management of containerized applications. It groups containers that make up an application into logical units for easy management and discovery.
The name Kubernetes originates from Greek, meaning helmsman or pilot. K8s as an abbreviation results from counting the eight letters between the "K" and the "s". Google open-sourced the Kubernetes project in 2014. Kubernetes combines over 15 years of Google's experience running production workloads at scale with best-of-breed ideas and practices from the community.
Orchestrators
Kubernetes orchestrators help in deploying and managing application/ docker Dynamically helps in Deploying the app with zero downtime updates and is easy to scale and also has self-healing containers.
For ex: In an Orchestra all the people who are playing drumsticks, triumph, etc can be considered microservices whereas the orchestrator can be considered as Kubernetes.
An application that follows all the principles of Orchestrators and apps that can run on top of Kubernetes is called as CloudNative Applications.
Why use Kubernetes?
A container-orchestration engine is used to automate deploying, scaling, and managing containerized applications on a group of servers. As I mentioned above, Kubernetes makes it easier for us to manage containers and ensure that there is no downtime. To give you an example, suppose one of the containers that you are running went down, it won’t take much effort to restart it manually. But suppose a large number of containers went down, wouldn’t it be easier if the system handles this issue automatically? Kubernetes can do this for us. Some of the features include scheduling, scaling, load balancing, fault tolerance, deployment, automated rollouts, rollbacks, etc.
Architecture of Kubernetes
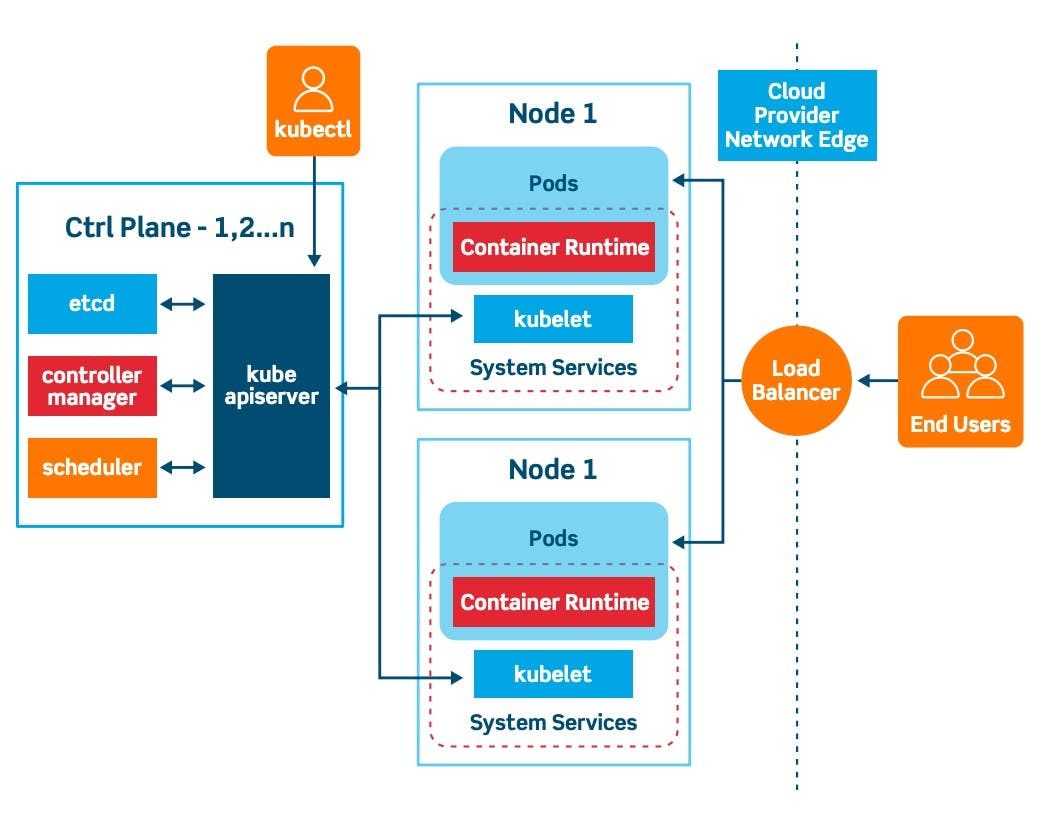
Kubernetes Architecture consists of the master node or control plane is a collection of various components which helps us in managing the overall health of the cluster and manages other workers' nodes. Worker nodes are nothing but can be treated as Virtual Machines / physical servers running within a data center.
Kubernetes has a decentralized architecture that does not handle tasks sequentially. It functions based on a declarative model and implements the concept of a desired state.
Control Plane:
The master makes global decisions about the cluster and they also detect and respond to cluster events like starting up a new pod when a deployment’s field “replicas” is unsatisfied. (replicas dictate the number of identical structures of nodes to be kept at any given point in time)
Master components, set up scripts typically start all master components on the same machine and do not run user containers on this machine for the sake of simplicity.
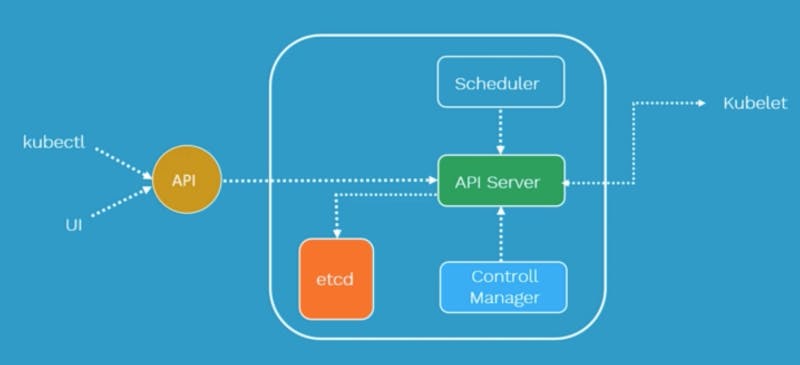
~Components of Control Plane(Master node)
Kube API server
Gatekeeper for the entire cluster.Accepts commands that view or change the state of the cluster, including that of the launching pods.
It authenticates requests and determines if they are authorized and valid, thereby managing admission control.
This is the component of the master that receives the API call and appropriately serves it.
It is the Kube API server that also establishes a connection with the kubelet. (kubelets can be considered as a Command line for kubernetes).
etcd
It is the clusters database.
It reliably stores the state of the cluster, including all information with regard to cluster configuration and more dynamic information like what nodes need to be running, etc. As you can see in the diagram the Kube API server interacts directly with etcd.
Any component of Kubernetes can query etcd to understand the state of the cluster so this is going to be the single source of truth for all the nodes, components, and masters that are forming the Kubernetes cluster.
Kube-Scheduler
It is responsible for physically scheduling Pods across multiple nodes. Depending upon the constraints mentioned in the configuration file, scheduler schedules these Pods accordingly.
For example, if you mention CPU has 2 core, memory is 4 GB, DiskType is SSD, etc. Once this artifact is passed to API server, the scheduler will look for the appropriate nodes that meet these criteria & will schedule the Pods accordingly.
Kube Controller Manager
It continuously monitors the state of the cluster via the kube API server. When the current state does not match the desired state, it makes changes to achieve the desired state.(A reservation was made but since no table was vacant the manager decides to add another table to accommodate the customer).
It is called the controller manager as Kubernetes objects are maintained by loops of code called controllers.
The controller also communicates with important information if a node goes offline.
Kube cloud manager
cloud-controller-manager runs controllers that interact with the underlying cloud providers.
cloud-controller-manager allows the cloud vendor’s code and the Kubernetes code to evolve independently of each other. In prior releases, the core Kubernetes code was dependent upon cloud-provider-specific code for functionality.
It’s responsible for features like load balancing, storage volumes as and when required.
Worker nodes
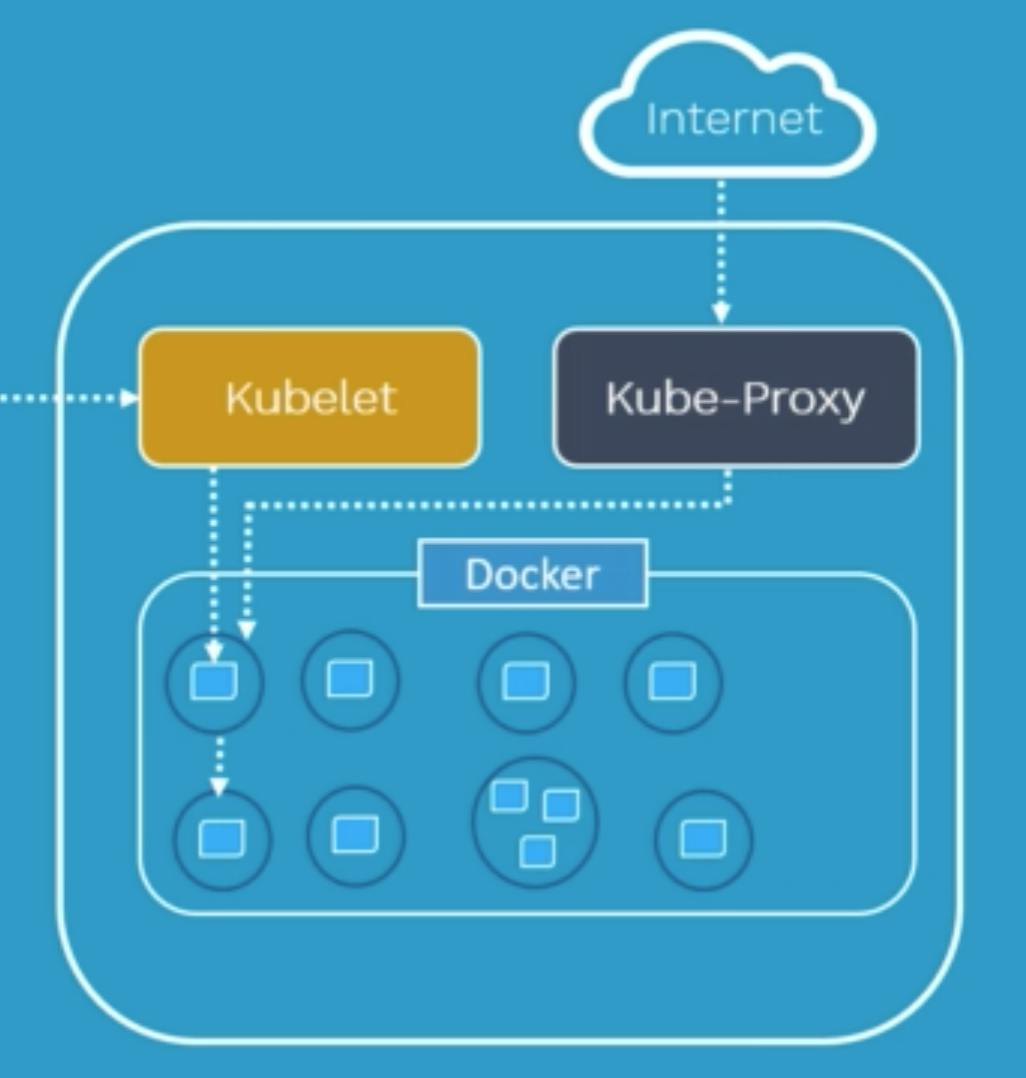
~Components of worker nodes
Kubelet
It is the kubernetes agent on each node. When the start of a pod is required, a connection kubelet is required.
The kubelet uses the container runtime to start the pod, monitors its lifecycle, checks for the readiness, etc.
The Kubelet reports to the Kube API server. kubelets can be considered as a Command line for Kubernetes.
Kube-proxy
Responsible for maintaining the entire network configuration. It maintains the distributed network across all the nodes, across all the pods, and all containers. Also exposes services to the outside world.
It is the core networking component inside Kubernetes. Kube-proxy maintains network rules on nodes which allows it to maintain network connectivity
Pod
A scheduling unit in Kubernetes. Like a virtual machine in the virtualization world. In the Kubernetes world, we have a Pod. Each Pod consists of one or more containers.
- We interact and manage containers through Pods. With the help of Pods, we can deploy multiple dependent containers together. Pod acts as a Wrapper around these containers.
Containers
- Containers are Runtime Environments for containerized applications. We run container applications inside the containers.
- These containers reside inside Pods. Containers are designed to run Micro-services.
That's all for now. Please like, share, and comment if you found this information informative. If you have any questions, please leave them in the comments section and I will do my best to answer them. Thanks for reading. Any feedbacks are welcome!! :) Connect me onTwitter | Github